粗粒度 code 看长时结构,细粒度 code 补局部纹理,层级之间不再共享同一帧率。
2024 / Multi-Scale Codec
SNAC
SNAC 的核心不是把 codec 再堆更深,而是直接改写离散 token 的时间组织方式。它让不同量化层工作在不同 temporal resolution 上,从一开始就把“怎样让音频 token 更适合长上下文模型”放进结构设计里。
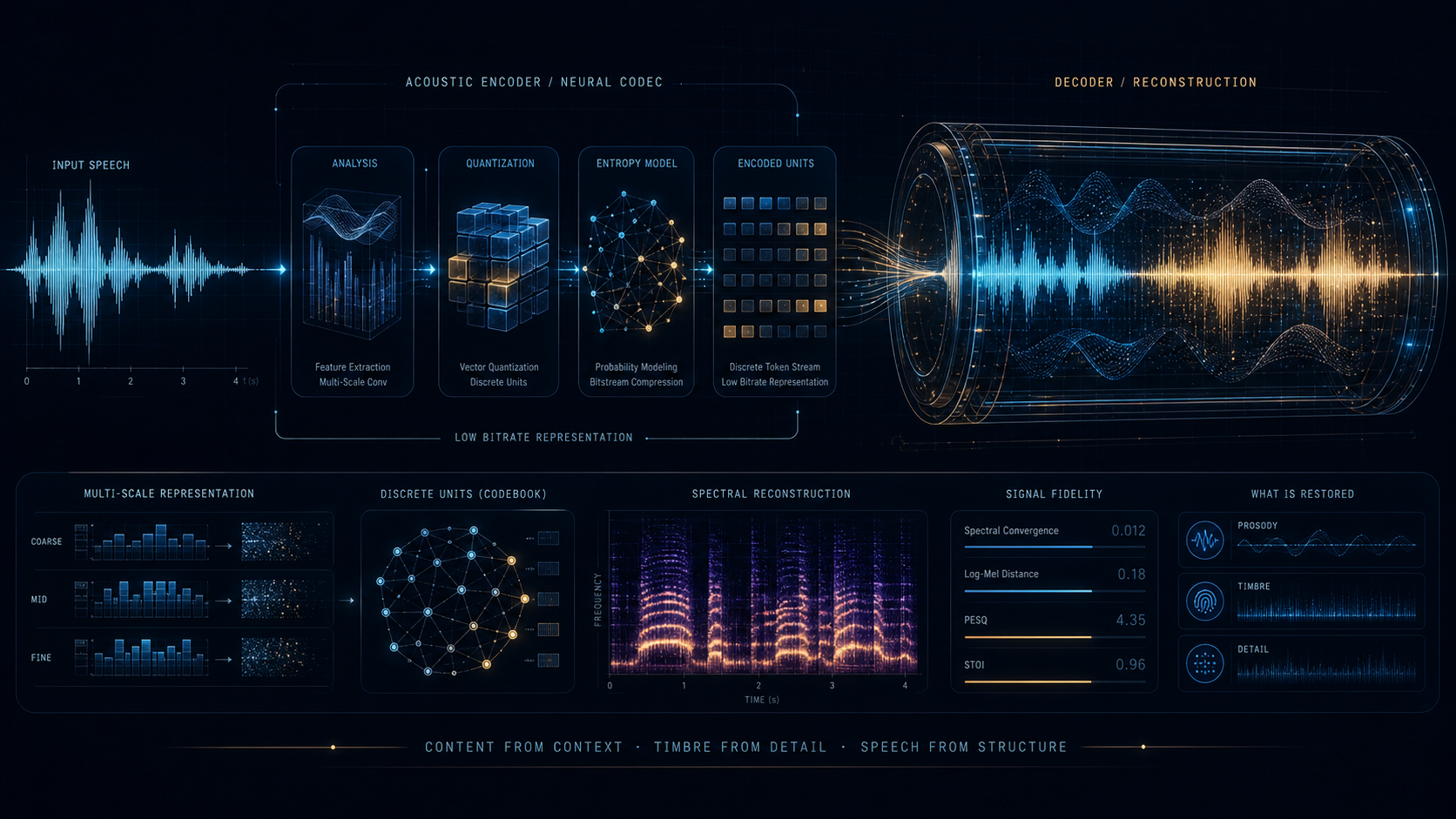
它追求的不是只在短窗口里“听起来还行”,而是在更低 token 密度下保住长时间组织。
当粗层 token 速率降低后,同样长度的上下文窗口就能覆盖更长的时间范围。
Core Route
SNAC 之所以重要,是因为它把问题从“怎样把音频压得更好”前移到了“怎样让离散 token 本身长得更适合被模型读取”。
为什么同一帧率的 RVQ 不够用了
传统 RVQ 把所有 codebook 都放在同一时间分辨率上,虽然实现直观,但高层结构和长时依赖没有被显式提出来。接到 Transformer 之后,context window 很快就会被高频 token 吃满。
SNAC 改的不是 codebook 数量,而是时间组织
它仍然使用残差量化,但不同层的 token 长度已经不一样了。粗层更新更慢、覆盖更长时间;细层更新更快、补充局部细节。这让离散表示第一次在时间轴上有了明确层级。
为什么这会直接改善长上下文建模
一旦粗粒度 token 的帧率显著下降,同样大小的上下文窗口就能覆盖几分钟级的结构,而不是只够看几秒。对音乐段落、节奏结构、长语音 prosody 来说,这种变化是根本性的。
除了多尺度量化,它还做了哪些细节增强
论文里还加入了 noise blocks、depthwise convolutions 和 local windowed attention。这些不是喧宾夺主的卖点,但它们说明作者不是只提概念,而是认真把多尺度 token 方案做成了可运行的 codec。