目标非常明确,就是把离散语音前端压到极低速率,同时仍保持较高的语音可用性。
2025 / Spoken Language Modeling
HH-Codec
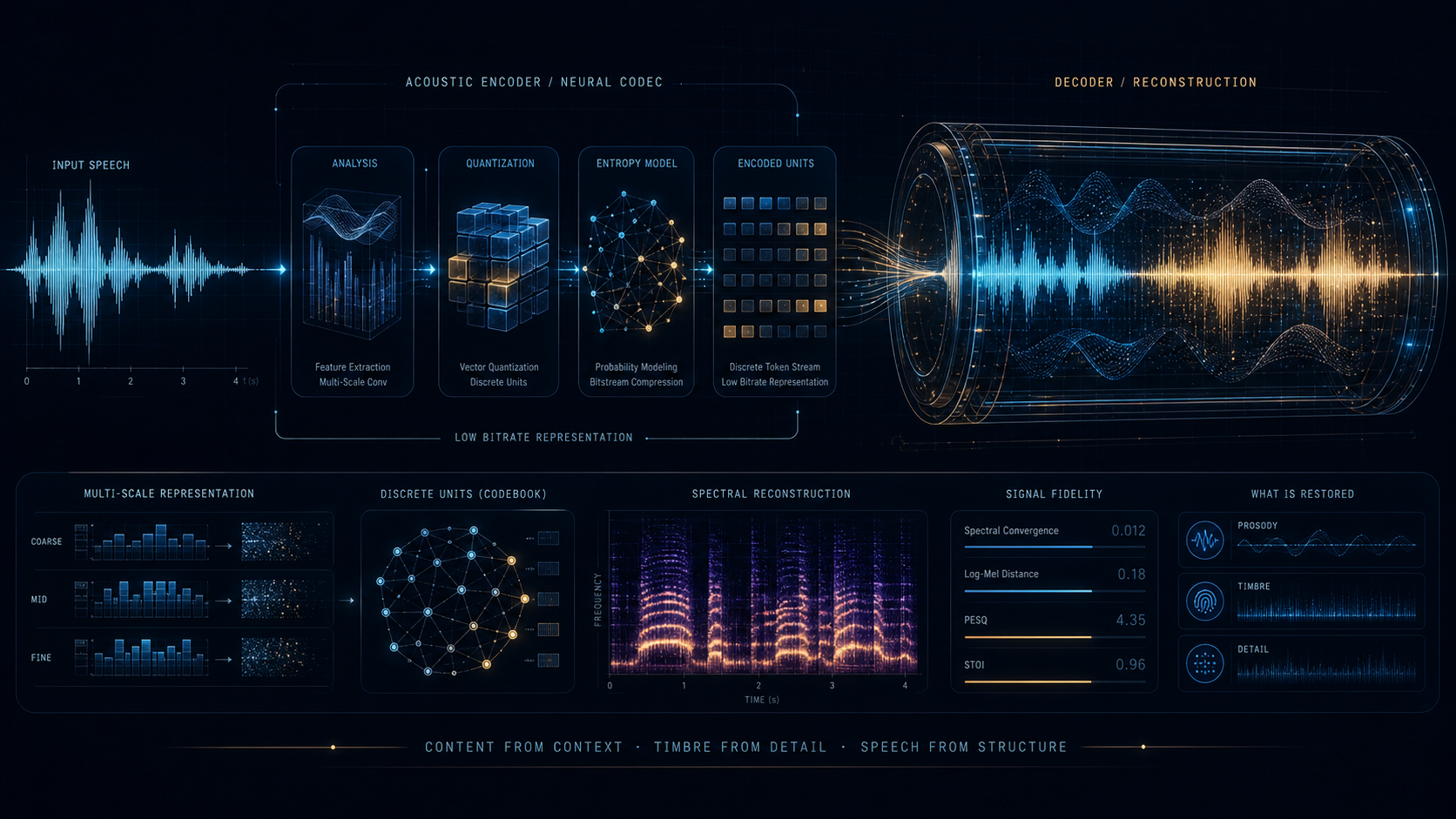
HH-Codec 的目标非常直接:给 spoken language modeling 提供极低 token 速率、极低带宽、但仍保持较高重建质量的离散语音前端。它代表的是“为了语音生成模型而做 codec”这条线。
相比多量化器并行流,这条路线更适合大规模 speech-to-speech 系统中的推理预算。
它不是只追求更低 bitrate,而是同步强化重建稳定性和生成模型适配性。
Core Route
HH-Codec 把“给 spoken language model 做前端”这件事写得非常露骨,所以它特别适合放在这组新路线里,作为一个目标导向极强的代表。
为什么 single-quantizer inference 值得单独强调
很多并行多量化器结构在大规模语音生成系统里会带来额外复杂度。HH-Codec 的做法更激进:尽量把推理路径压到单量化器级别,直接服务实际生成链路的吞吐和延迟预算。
MLP refine 和 BigVGAN 在这里各自负责什么
前者用于把离散量化后的表示进一步整理成更适合后续重建的 latent,后者则承担高质量声码器角色,把 mel 级信息稳定地恢复成最终音频。这种分工很符合“前端 token 尽量轻,后端重建单独强化”的工程思路。
dual supervision 和 progressive training 解的是什么问题
极低码率下,模型很容易在可懂度、自然度和训练稳定性之间互相拉扯。双重监督和渐进训练的意义,就是让系统不要为了压缩率一下子把重建质量和后续适配性同时丢掉。
它和 DualCodec / LongCat 这类路线的差别是什么
HH-Codec 并不强调双流语义增强或并行语义 / 声学 token,它更像是先把“极低 token 速率的 spoken LM 前端”这个目标做得足够直接、足够实用,然后再处理重建质量问题。