它不再假定一套 token 统一承担所有层级信息,而是把内容和细节在结构上先拆开。
2025 / Speech Large Language Models
LongCat-Audio-Codec
LongCat-Audio-Codec 已经把目标说得很清楚了:它是一套给 speech large language models 准备的 tokenizer / detokenizer 方案。最重要的结构动作,是 semantic token 和 acoustic token 并行生成,再接 streaming detokenizer。
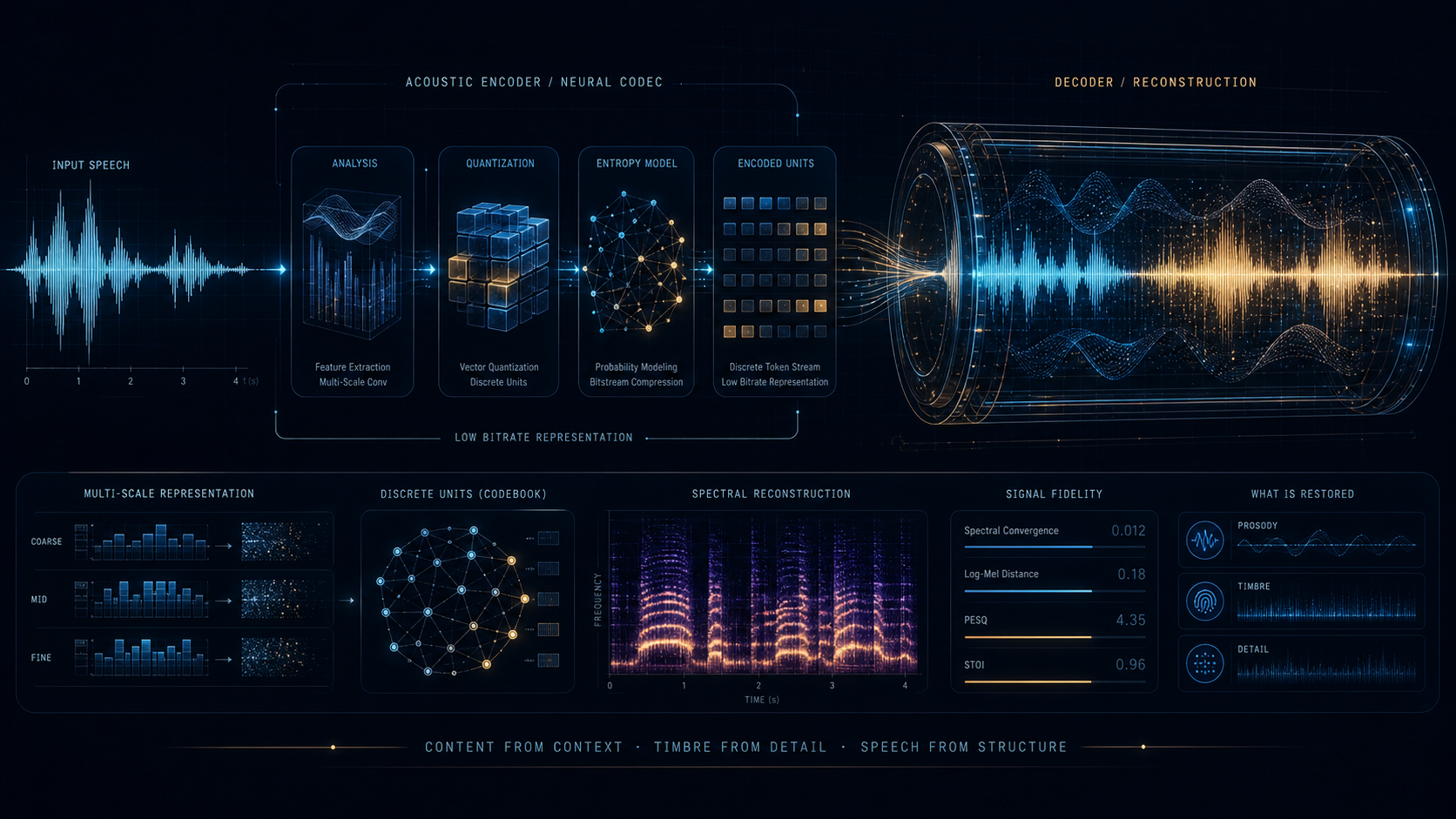
超低帧率说明它从一开始就在为长上下文和工业级 speech LLM 预算服务。
不是只做一个 tokenizer 论文,而是把生成端的流式恢复也一起设计进来了。
Core Route
LongCat-Audio-Codec 真正重要的地方,在于它已经不是“给 codec 找下游”了,而是直接按 speech LLM 的需求来反推 tokenizer / detokenizer 应该长什么样。
为什么要并行生成 semantic token 和 acoustic token
这等于在结构上承认了一件事:高层内容信息和低层声学细节不一定适合被同一套 token 完全承载。并行双 token 的好处,就是让上层模型和下层重建模块分别读取自己更关心的那部分信息。
16.67 Hz 的超低帧率在这里意味着什么
它意味着 speech LLM 在生成或理解时,可以用更小的 token 预算覆盖更长时间范围。这对多轮语音交互、长语音上下文和工业部署都非常实际,不是只对论文表格好看。
可调 acoustic codebook 代表了什么取舍
LongCat 不是用一种固定强度的声学细节恢复方案,而是允许 acoustic 侧的容量做调整。这样一来,同一条主线就可以针对不同质量预算、延迟预算和部署场景作更细的平衡。
streaming detokenizer 为什么值得单独看
很多工作停在 tokenizer 这一步,LongCat 则把解码端的流式恢复一并纳入设计。只有这一步也成立,speech LLM 的整条语音链路才算真正在工程上闭环。