结构从一开始就为 Transformer 化的表示学习服务,而不是只在旧主干上做小修小补。
2024 / Stability AI
Stable Codec
Stable Codec 代表的是另一条明显的推进方向:把低码率 speech codec 更彻底地做成 Transformer 系统,并用 FSQ 这类更规整的离散瓶颈来替代传统 RVQ 叙事。
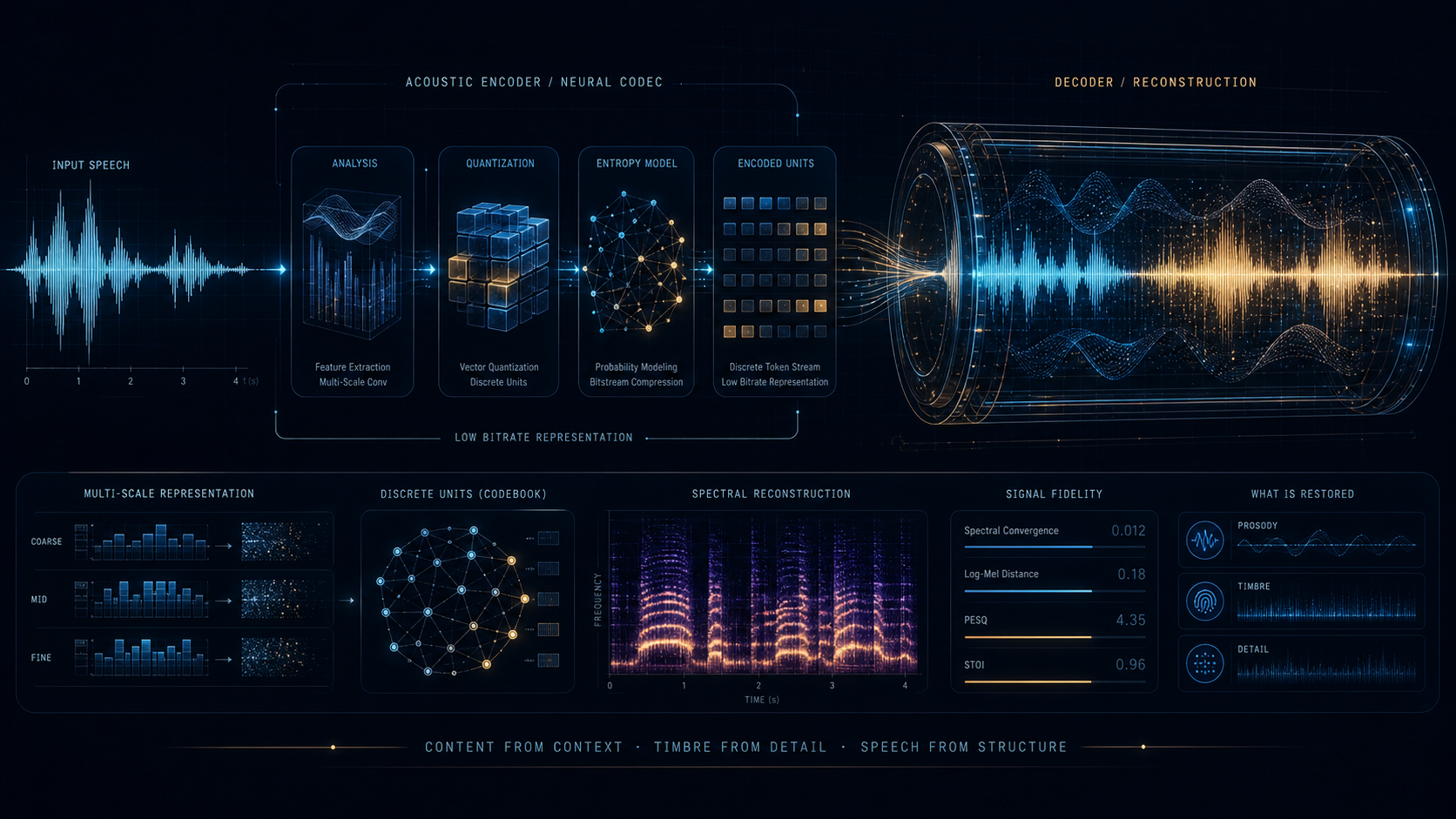
它瞄准的是更低码率的语音链路,目标非常明确,不想在高码率区间里做模糊叙事。
官方仓库还给出了带 CTC phoneme regression 微调的版本,说明作者很在意 latent 里的语义可读性。
Core Route
Stable Codec 把“codec 也可以按大模型思路重写”这件事讲得很直接:Transformer 负责建模,FSQ 负责离散瓶颈,目标则锁定低码率 speech coding。
为什么这里要走 Transformer codec
如果说 SoundStream / EnCodec 时代更重视低时延和工程稳定性,那么 Stable Codec 更像是在问:当我们愿意把 codec 本身做成更强的序列建模系统时,低码率 speech coding 能被推进到什么程度。
FSQ 瓶颈和 RVQ 的区别在哪里
RVQ 的长处是残差逐层补细节,FSQ 则更强调规则化、因子化的离散表示方式。Stable Codec 把 FSQ 放到系统正中央,说明作者不是在沿袭旧骨架,而是在重新组织离散瓶颈的设计语言。
它为什么只盯着低码率 16 kHz speech
这反而让路线更清楚。它不试图用一个叙事同时覆盖所有域,而是明确针对低码率语音场景,把模型容量、离散瓶颈和重建目标都往同一个方向收紧。
后续 CTC phoneme regression 暗示了什么
这说明作者已经不满足于“听起来像”了,还想让 latent 更容易携带可读的语音内容结构。换句话说,这条线也在慢慢向语义增强前端靠过去。