目标不是只做压缩,而是让离散声学 token 更适合后续模型直接读取和建模。
2024 / Acoustic Discrete Tokenizer
WavTokenizer
WavTokenizer 的重点很直接:把 codec 输出做成更高效、更适合音频语言模型使用的离散前端。它不只是追求重建质量,而是明确围绕 token 效率和 downstream modeling 来设计。
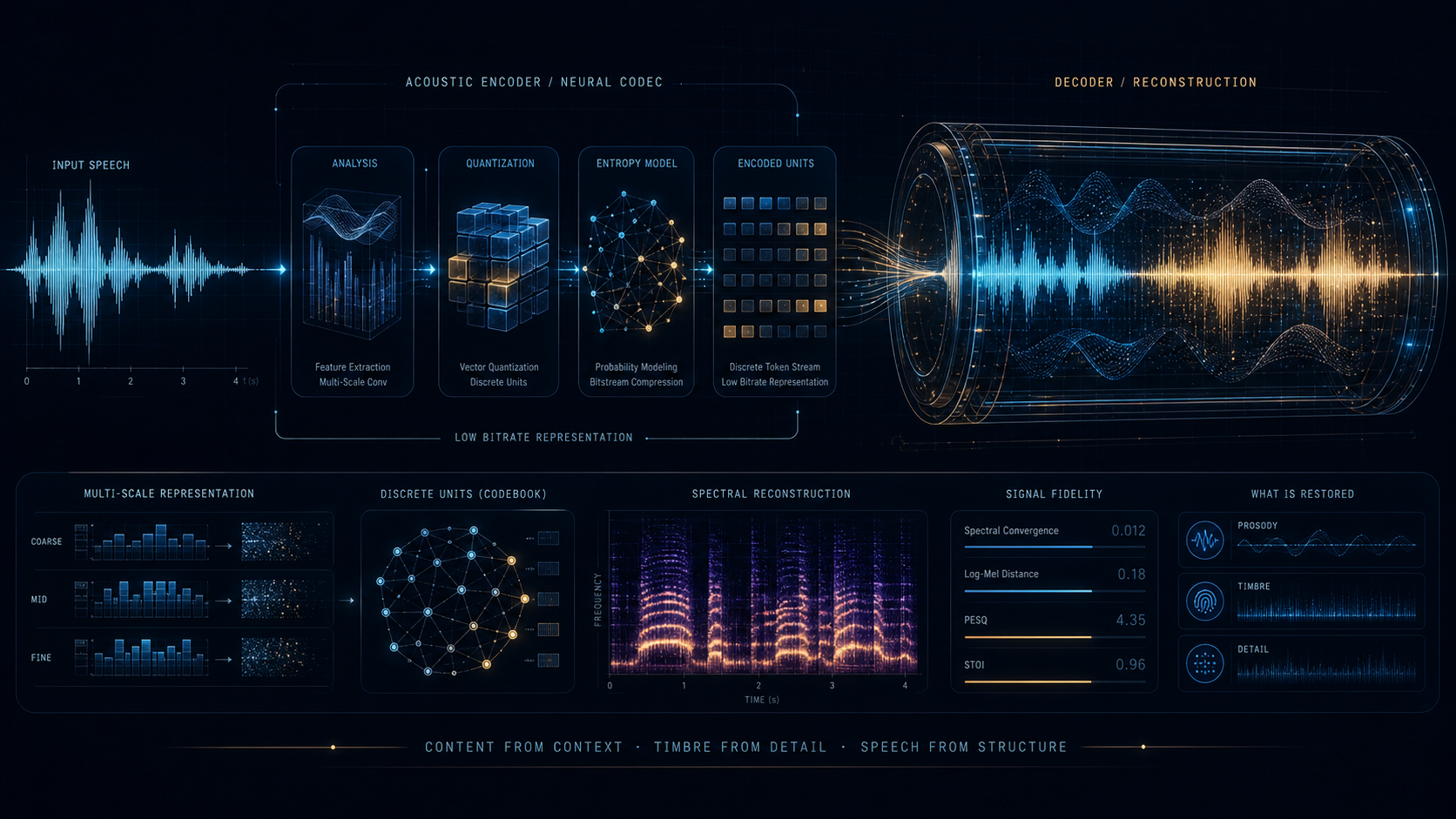
Figure Note
这一页故意不自己画结构图。WavTokenizer 官方公开得最完整的是结果图和 README 说明,所以页面重点放在技术路线本身:低 token 速率、高效离散前端,以及面向 audio language modeling 的接口思路。
比传统高频率离散码更克制,也更贴近后续长上下文和生成模型的预算。
它希望这个前端不只限于单一语音域,而是尽量兼顾更广的音频建模任务。
Core Route
WavTokenizer 最核心的转向,是不再把 codec 当成单独的压缩模块看,而是直接把它当成音频语言模型的离散前端接口来优化。
为什么它强调 tokenizer,而不只写 codec
这个命名本身已经说明问题了。作者关心的不只是“能否压缩”,而是“压出来的 token 是否足够高效、足够有信息、能否被上层模型方便消费”。这比单纯刷一个重建分数更贴近后续系统接口。
40 / 75 tokens per second 解决了什么
token 速率被压下来之后,长上下文建模的成本会明显下降。尤其对音频语言模型来说,token 太密会直接吃掉上下文窗口;WavTokenizer 的路线就是尽量用更少的 token 保留足够多的信息。
为什么它还强调 rich semantic information
这说明它已经不满足于纯声学细节压缩了。虽然整体仍放在声学编码器空间里,但作者很清楚:如果 token 里没有足够高层的信息,后面的语言模型根本不好用。
它和 Mimi / DualCodec 这类路线有什么差别
WavTokenizer 没有像 Mimi、DualCodec 那样直接把语义增强写进结构叙事里,它更像是从“高效 acoustic tokenizer”这条路径迂回逼近同一个目标。所以它是另一种更工程接口导向的解法。